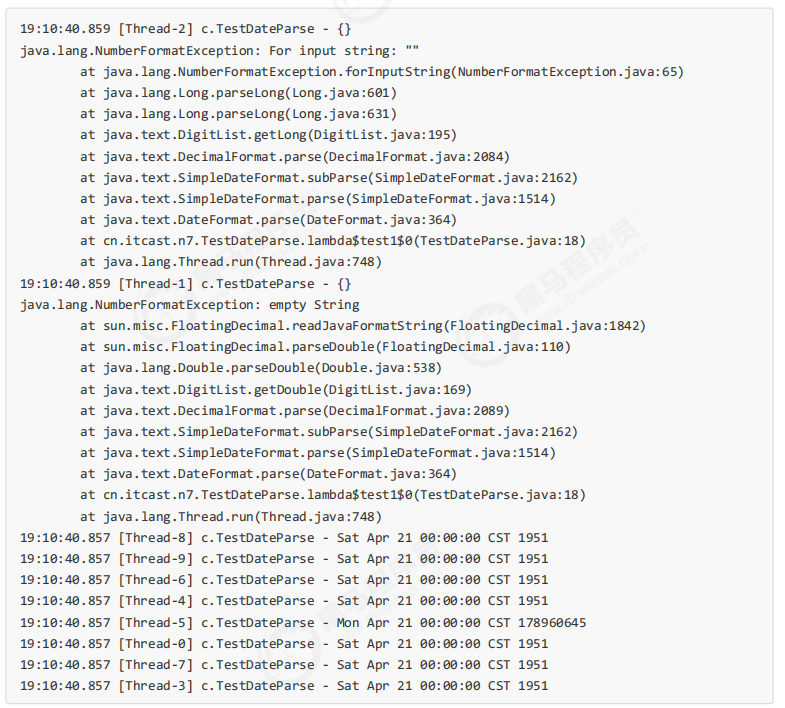
日期转换的问题 下面的代码在运行时,由于 SimpleDateFormat 不是线程安全的 ,有很大几率出现 java.lang.NumberFormatException 或者出现不正确的日期解析结果
1 2 3 4 5 6 7 8 9 10 11 SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd" );for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { try { log.debug("{}" , sdf.parse("1951-04-21" )); } catch (Exception e) { log.error("{}" , e); } }).start(); }
例如:
思路 - synchronized同步锁 这样虽能解决问题,但带来的是性能上的损失,并不算很好:
1 2 3 4 5 6 7 8 9 10 11 12 13 SimpleDateFormat sdf = new SimpleDateFormat ("yyyy-MM-dd" );for (int i = 0 ; i < 50 ; i++) { new Thread (() -> { synchronized (sdf) { try { log.debug("{}" , sdf.parse("1951-04-21" )); } catch (Exception e) { log.error("{}" , e); } } }).start(); }
如果一个对象在不能够修改其内部状态(属性),那么它就是线程安全的,因为不存在并发修改啊!
这样的对象在 Java 中有很多,例如在 Java 8 后,提供了一个新的日期格式化类:
1 2 3 4 5 6 7 8 DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd" );for (int i = 0 ; i < 10 ; i++) { new Thread (() -> { LocalDate date = dtf.parse("2018-10-01" , LocalDate::from); log.debug("{}" , date); }).start(); }
可以看 DateTimeFormatter 的文档:
1 2 @implSpec This class is immutable and thread-safe.
不可变对象,实际是另一种避免竞争的方式。
不可变设计 另一个大家更为熟悉的 String 类也是不可变的,以它为例,说明一下不可变设计的要素
1 2 3 4 5 6 7 8 public final class String implements java .io.Serializable, Comparable<String>, CharSequence { private final char value[]; private int hash; }
final 的使用 发现该类、类中所有属性都是 final 的
属性用 final 修饰保证了该属性是只读的,不能修改
类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
保护性拷贝 (defensive copy) 但有同学会说,使用字符串时,也有一些跟修改相关的方法啊,比如 substring 等,
那么下面就看一看这些方法是如何实现的,就以 substring 为例:
1 2 3 4 5 6 7 8 9 10 public String substring (int beginIndex) { if (beginIndex < 0 ) { throw new StringIndexOutOfBoundsException (beginIndex); } int subLen = value.length - beginIndex; if (subLen < 0 ) { throw new StringIndexOutOfBoundsException (subLen); } return (beginIndex == 0 ) ? this : new String (value, beginIndex, subLen); }
发现其内部是调用 String 的构造方法创建了一个新字符串,
再进入这个构造看看,是否对 final char[] value 做出了修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public String (char value[], int offset, int count) { if (offset < 0 ) { throw new StringIndexOutOfBoundsException (offset); } if (count <= 0 ) { if (count < 0 ) { throw new StringIndexOutOfBoundsException (count); } if (offset <= value.length) { this .value = "" .value; return ; } } if (offset > value.length - count) { throw new StringIndexOutOfBoundsException (offset + count); } this .value = Arrays.copyOfRange(value, offset, offset+count); }
结果发现也没有,构造新字符串对象时,会生成新的 char[] value,对内容进行复制 。
这种通过创建副本对象来避免共享的手段称之为【保护性拷贝(defensive copy)】
模式之享元 (池) 简介 定义 英文名称:Flyweight pattern. 当需要重用数量有限的同一类对象 时 .
wikipedia: A flyweight is an object that minimizes memory usage by sharing as much data as possible with other similar objects
flyweight 是一种通过与其他类似对象共享尽可能多的数据来最小化内存使用的对象
出自 “Gang of Four” design patterns
归类 Structual patterns
体现 包装类 在JDK中 Boolean,Byte,Short,Integer,Long,Character 等包装类提供了 valueOf 方法,例如 Long 的valueOf 会缓存 -128~127 之间的 Long 对象,在这个范围之间会重用对象,大于这个范围,才会新建 Long 对象:
1 2 3 4 5 6 7 public static Long valueOf (long l) { final int offset = 128 ; if (l >= -128 && l <= 127 ) { return LongCache.cache[(int )l + offset]; } return new Long (l); }
注意:
2.2 String 串池 参见jvm课程
2.3 BigDecimal BigInteger
这些类的单个方法是线程安全的,但多个方法的组合使用如果也要保证线程安全就需要使用锁来保护了
DIY 自定义数据库连接池 例如:一个线上商城应用,QPS 达到数千,如果每次都重新创建和关闭数据库连接,性能会受到极大影响。
这时预先创建好一批连接,放入连接池。一次请求到达后,从连接池获取连接,使用完毕后再还回连接池,这样既节约了连接的创建和关闭时间,也实现了连接的重用,不至于让庞大的连接数压垮数据库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 class Pool { private final int poolSize; private Connection[] connections; private AtomicIntegerArray states; public Pool (int poolSize) { this .poolSize = poolSize; this .connections = new Connection [poolSize]; this .states = new AtomicIntegerArray (new int [poolSize]); for (int i = 0 ; i < poolSize; i++) { connections[i] = new MockConnection ("连接" + (i+1 )); } } public Connection borrow () { while (true ) { for (int i = 0 ; i < poolSize; i++) { if (states.get(i) == 0 ) { if (states.compareAndSet(i, 0 , 1 )) { log.debug("borrow {}" , connections[i]); return connections[i]; } } } synchronized (this ) { try { log.debug("wait..." ); this .wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } } public void free (Connection conn) { for (int i = 0 ; i < poolSize; i++) { if (connections[i] == conn) { states.set(i, 0 ); synchronized (this ) { log.debug("free {}" , conn); this .notifyAll(); } break ; } } } } class MockConnection implements Connection { private String name; public MockConnection (String name) { this .name = name; } @Override public String toString () { return "MockConnection{" + "name='" + name + '\'' + '}' ; } @Override public Statement createStatement () throws SQLException { return null ; } @Override public PreparedStatement prepareStatement (String sql) throws SQLException { return null ; } @Override public CallableStatement prepareCall (String sql) throws SQLException { return null ; } @Override public String nativeSQL (String sql) throws SQLException { return null ; } @Override public void setAutoCommit (boolean autoCommit) throws SQLException { } @Override public boolean getAutoCommit () throws SQLException { return false ; } @Override public void commit () throws SQLException { } @Override public void rollback () throws SQLException { } @Override public void close () throws SQLException { } @Override public boolean isClosed () throws SQLException { return false ; } @Override public DatabaseMetaData getMetaData () throws SQLException { return null ; } @Override public void setReadOnly (boolean readOnly) throws SQLException { } @Override public boolean isReadOnly () throws SQLException { return false ; } @Override public void setCatalog (String catalog) throws SQLException { } @Override public String getCatalog () throws SQLException { return null ; } @Override public void setTransactionIsolation (int level) throws SQLException { } @Override public int getTransactionIsolation () throws SQLException { return 0 ; } @Override public SQLWarning getWarnings () throws SQLException { return null ; } @Override public void clearWarnings () throws SQLException { } @Override public Statement createStatement (int resultSetType, int resultSetConcurrency) throws SQLException { return null ; } @Override public PreparedStatement prepareStatement (String sql, int resultSetType, int resultSetConcurrency) throws SQLException { return null ; } @Override public CallableStatement prepareCall (String sql, int resultSetType, int resultSetConcurrency) throws SQLException { return null ; } @Override public Map<String, Class<?>> getTypeMap() throws SQLException { return null ; } @Override public void setTypeMap (Map<String, Class<?>> map) throws SQLException { } @Override public void setHoldability (int holdability) throws SQLException { } @Override public int getHoldability () throws SQLException { return 0 ; } @Override public Savepoint setSavepoint () throws SQLException { return null ; } @Override public Savepoint setSavepoint (String name) throws SQLException { return null ; } @Override public void rollback (Savepoint savepoint) throws SQLException { } @Override public void releaseSavepoint (Savepoint savepoint) throws SQLException { } @Override public Statement createStatement (int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException { return null ; } @Override public PreparedStatement prepareStatement (String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException { return null ; } @Override public CallableStatement prepareCall (String sql, int resultSetType, int resultSetConcurrency, int resultSetHoldability) throws SQLException { return null ; } @Override public PreparedStatement prepareStatement (String sql, int autoGeneratedKeys) throws SQLException { return null ; } @Override public PreparedStatement prepareStatement (String sql, int [] columnIndexes) throws SQLException { return null ; } @Override public PreparedStatement prepareStatement (String sql, String[] columnNames) throws SQLException { return null ; } @Override public Clob createClob () throws SQLException { return null ; } @Override public Blob createBlob () throws SQLException { return null ; } @Override public NClob createNClob () throws SQLException { return null ; } @Override public SQLXML createSQLXML () throws SQLException { return null ; } @Override public boolean isValid (int timeout) throws SQLException { return false ; } @Override public void setClientInfo (String name, String value) throws SQLClientInfoException { } @Override public void setClientInfo (Properties properties) throws SQLClientInfoException { } @Override public String getClientInfo (String name) throws SQLException { return null ; } @Override public Properties getClientInfo () throws SQLException { return null ; } @Override public Array createArrayOf (String typeName, Object[] elements) throws SQLException { return null ; } @Override public Struct createStruct (String typeName, Object[] attributes) throws SQLException { return null ; } @Override public void setSchema (String schema) throws SQLException { } @Override public String getSchema () throws SQLException { return null ; } @Override public void abort (Executor executor) throws SQLException { } @Override public void setNetworkTimeout (Executor executor, int milliseconds) throws SQLException { } @Override public int getNetworkTimeout () throws SQLException { return 0 ; } @Override public <T> T unwrap (Class<T> iface) throws SQLException { return null ; } @Override public boolean isWrapperFor (Class<?> iface) throws SQLException { return false ; } }
使用连接池:
1 2 3 4 5 6 7 8 9 10 11 12 13 Pool pool = new Pool (2 );for (int i = 0 ; i < 5 ; i++) { new Thread (() -> { Connection conn = pool.borrow(); try { Thread.sleep(new Random ().nextInt(1000 )); } catch (InterruptedException e) { e.printStackTrace(); } pool.free(conn); }).start(); }
以上实现没有考虑:
连接的动态增长与收缩
连接保活(可用性检测)
等待超时处理
分布式 hash
对于关系型数据库,有比较成熟的连接池实现,例如c3p0, druid等
对于更通用的对象池,可以考虑使用apache commons pool,例如redis连接池可以参考jedis中关于连接池的实现
原理之 final 设置 final 变量的原理 理解了 volatile 原理,再对比 fifinal 的实现就比较简单了
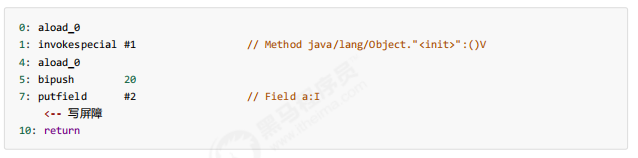
1 2 3 public class TestFinal { final int a = 20 ; }
字节码
发现 final 变量的赋值也会通过 putfifield 指令来完成,同样在这条指令之后也会加入写屏障 ,保证在其它线程读到它的值时不会出现为 0 的情况
获取 final 变量的原理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class TestFinal { static int A = 10 ; static int B = Short.MAX_VALUE+1 ; final int a = 20 ; final int b = Integer.MAX_VALUE; final void test1 () { final int c = 30 ; new Thread (()->{ System.out.println(c); }).start(); final int d = 30 ; class Task implements Runnable { @Override public void run () { System.out.println(d); } } new Thread (new Task ()).start(); } } class UseFinal1 { public void test () { System.out.println(TestFinal.A); System.out.println(TestFinal.B); System.out.println(new TestFinal ().a); System.out.println(new TestFinal ().b); new TestFinal ().test1(); } } class UseFinal2 { public void test () { System.out.println(TestFinal.A); } }
需要从字节码层面看这段代码
匿名内部类访问的局部变量为什么必须要用final修饰
参考 https://blog.csdn.net/tianjindong0804/article/details/81710268
匿名内部类之所以可以访问局部变量,是因为在底层将这个局部变量的值传入到了匿名内部类中,并且以匿名内部类的成员变量的形式存在,这个值的传递过程是通过匿名内部类的构造器完成的。
为什么需要用final修饰局部变量呢?
按照习惯,我依旧先给出问题的答案:用final修饰实际上就是为了保护数据的一致性。
这里所说的数据一致性,对引用变量来说是引用地址的一致性,对基本类型来说就是值的一致性 。
final修饰符对变量来说,深层次的理解就是保障变量值的一致性。为什么这么说呢?因为引用类型变量其本质是存入的是一个引用地址,说白了还是一个值(可以理解为内存中的地址值)。用final修饰后,这个引用变量的地址值不能改变,所以这个引用变量就无法再指向其它对象了。
回到正题,为什么需要用final保护数据的一致性呢?
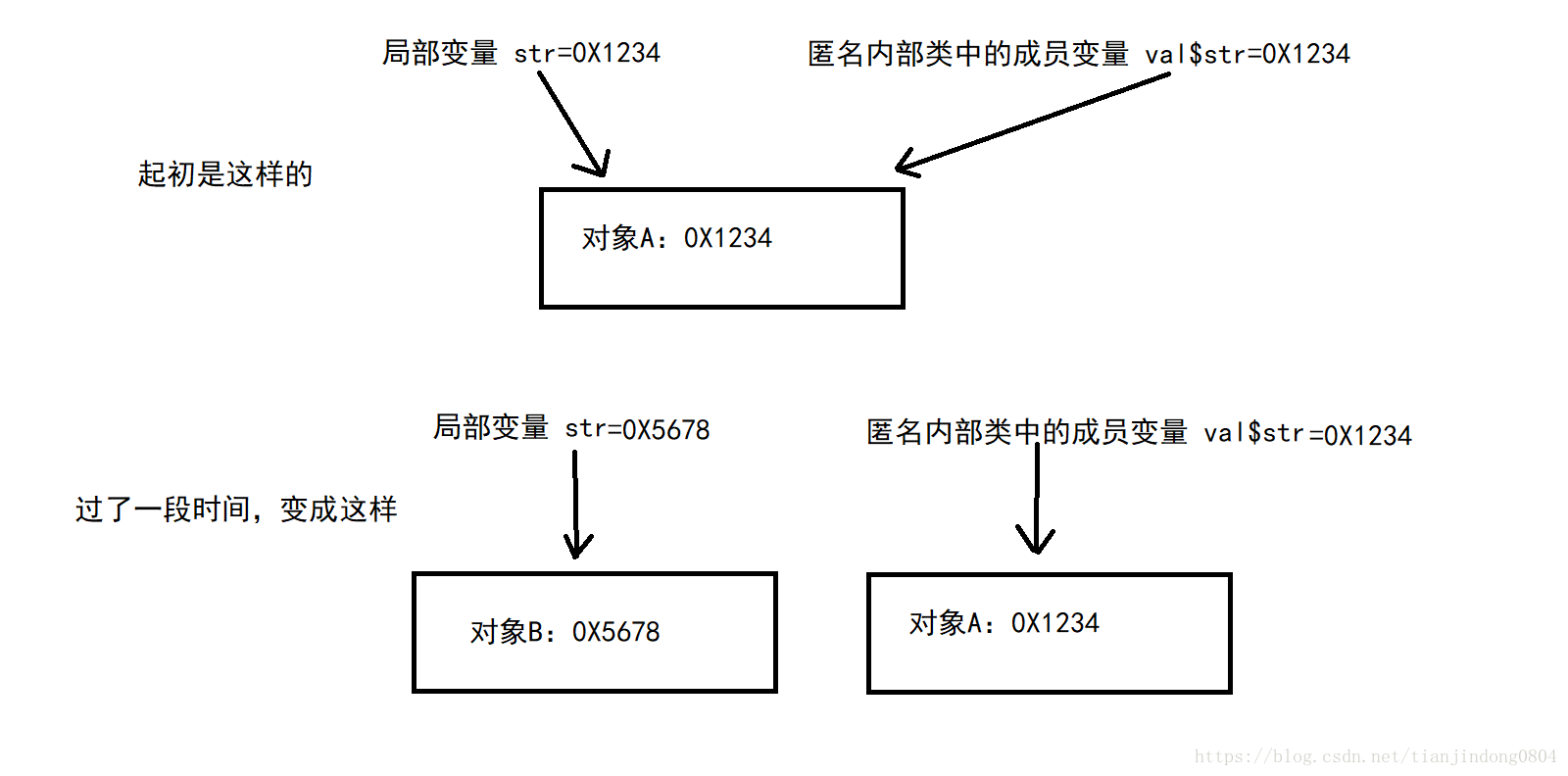
因为将数据拷贝完成后,如果不用final修饰,则原先的局部变量可以发生变化。这里到了问题的核心了,如果局部变量发生变化后,匿名内部类是不知道的(因为他只是拷贝了局部变量的值,并不是直接使用的局部变量)。这里举个例子:原先局部变量指向的是对象A,在创建匿名内部类后,匿名内部类中的成员变量也指向A对象。但过了一段时间局部变量的值指向另外一个B对象,但此时匿名内部类中还是指向原先的A对象。那么程序再接着运行下去,可能就会导致程序运行的结果与预期不同。
介绍到这里,关于为什么匿名内部类访问局部变量需要加 final 修饰符的原理基本讲完了。
那现在我们来谈一谈JDK8对这一问题的新的知识点。在JDK8中如果我们在匿名内部类中需要访问局部变量,那么这个局部变量不需要用final修饰符修饰。看似是一种编译机制的改变,实际上就是一个语法糖(底层还是帮你加了final )。但通过反编译没有看到底层为我们加上final,但我们无法改变这个局部变量的引用值,如果改变就会编译报错。
无状态 即无成员变量 在 web 阶段学习时,设计 Servlet 时为了保证其线程安全,都会有这样的建议,不要为 Servlet 设置成员变量,这种没有任何成员变量的类是线程安全的
因为成员变量保存的数据也可以称为状态信息,因此没有成员变量就称之为【无状态】
本章小结